Over the nearly five and a half years I’ve been at Clozemaster, I’ve reported literally dozens of mistakes (more than 80 in 2024 alone) in the pronunciation field for sentences in Russian from English. On some of these occasions, and in a thread from January 2021, “Pronunciation” field useless for Russian, but could be made useful, I’ve touched in a more general way on the fundamental problems with Clozemaster’s approach toward pronunciation in Russian. Today I am going to post an even more comprehensive overview, complete with (1) examples, (2) a description of how I’ve reported problems so far, and (3) a request for action.
Russian is a nearly phonetic language, meaning that there is a nearly one-to-one correspondence between letters and sounds. Monosyllabic words are generally unstressed (at the sentence level), and there is always a single accented syllable in a multisyllable word (with only one exception I’ve ever found, namely the word трёхно́гая). These factors should make pronunciation simple. However, there is one catch: the placement of the accented syllable is extremely hard for a non-native speaker to guess. This, coupled with the fact that “о” is pronounced “o” in an accented syllable, but “a” in an unaccented syllable, means that you cannot rely on the spelling of a word to tell you how it is pronounced. Note that there is one letter, “ё” (pronounced “yo”), that always receives the accent when it appears in a word. This should simplify matters. However, the dots are often omitted, at Clozemaster and elsewhere, making the letter look like “е” (pronunced “yeh”). This brings us back to confusion. Finally, there are many instances of multiple words with the same spelling that differ in the placement of the accent. In order to pronounce the word right, you need to understand the meaning and grammar of the sentence and its constituent words.
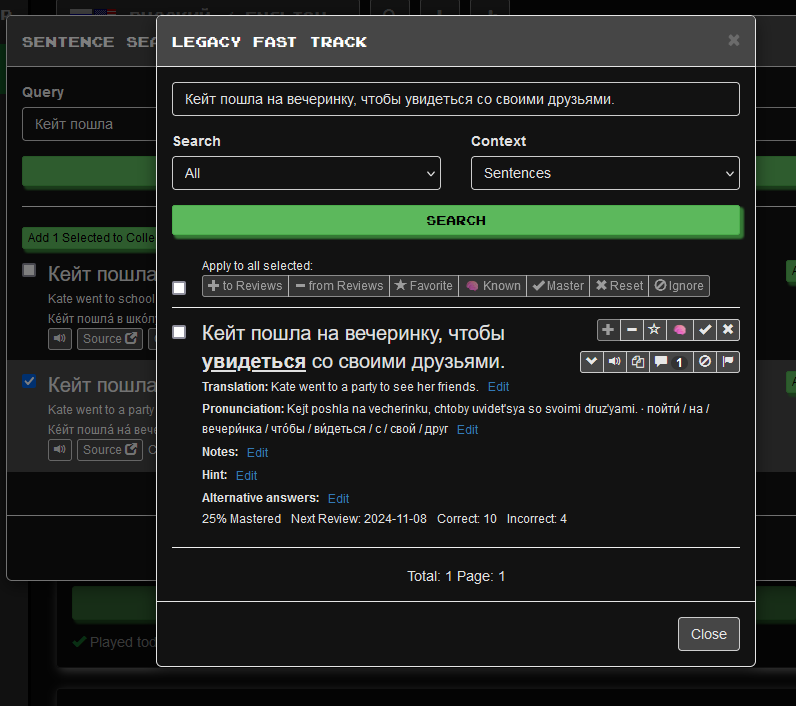
The handling of pronunciation at Clozemaster is inconsistent across sentences, with the result that the pronunciation field for a particular Russian sentence may contain any of the following:
(1) no pronunciation at all
(2) a pronunciation in Latin characters, which is of little value; it shows what anyone with even a few weeks’ acquaintance with the language should know (the correspondence between a Russian letter and its English counterpart), but fails to show the really important information, namely where the accent falls
(3) a pronunciation in Cyrillic characters, with accent marks, of the base/dictionary/lemma forms of the individual words in a sentence, which is also generally useless because the accent may shift when the word is declined
(4) a pronunciation in Cyrillic characters of the words in the sentence, with accents on some of the words, but with the accent mark omitted for key words (such as the cloze)
(5) a pronunciation in Cyrillic characters of all of the words in the sentence, with accent marks on all of them, even the monosyllabic ones, leaving the mistaken impression that those words are stressed at the sentence level
Finally, it looks pretty clear that at Clozemaster, an automatic stress-guesser with no knowledge of meaning or grammar has been used to provide pronunciations for words. When it encounters a word that could have either of two accented syllables, depending on its meaning or case, it often either guesses the wrong one or refuses to indicate the stress at all. Figuring out the error rate is not easy, but I would estimate the percentage of cases where the wrong stress is indicated for a particular word that I’m interested in could be as high as 15%. (@mike reported the rate of sentences with any pronunciation error at 6%. But given the fact I’m focusing on particular words/sentences, there might be a higher rate.) With such a high likelihood of error, I can’t trust the stress-guesser at all, which means that I need to look up the word at Wiktionary.
As a result, I have to go through the following time-consuming procedure every time I see a word whose pronunciation is not given or I don’t feel I can trust:
(1) Look it up at Wiktionary (which may take several steps, depending on whether the inflected form has a top-level page of its own).
(2) Copy the accented form into my clipboard.
(3) Determine whether the Clozemaster form matches the Wiktionary one.
(3.1) If the pronunciation is correct, copy the accented form, followed by the words “is correct”, into the pronunciation field for the Clozemaster sentence.
(3.2) If the pronunciation is not correct:
(3.3.1) Report the problem with the “Report” button and
(3.3.2) Report the problem in the Clozemaster forum and
(3.3.3) Edit the Clozemaster sentence itself in a way that lets me know both the right answer and that I’ve already reported an error. (My way of doing this is to copy the word into both the pronunciation field and the “Notes” field.)
As you can imagine, this is very time-consuming, even on a computer (as opposed to a phone), and even though I have set up shortcuts to make all this work as efficient as possible.
Why do I go to the trouble of reporting the problem with the “Report” button and posting about it on the forum? I suspect that if and when Clozemaster gets around to fixing these sentences, it will be more efficient to process the ones reported with the “Report” button. However, I have no way of tracking the sentences I’ve reported with this button, so I also post about them on the forum, which lets me see them in one place, together with the dates of the posts.
Now that I’ve described the problem, and how much trouble it’s causing me, here’s my call to action for @mike:
(1) Get someone to go through all the pronunciation mistakes that have been reported and fix the corresponding sentences. The work of finding the problems has been done for Clozemaster for free. Now take advantage of it. I haven’t received notification of a problem I’ve reported on a Russian sentence since July 2022, more than two years ago.
(2) Get rid of the Latin-character transcriptions. As I mentioned, they’re useless, and the fact that there’s a haphazard mix of these transcriptions with Cyrillic ones just (a) makes the site look less professional and (b) complicates the task of finding missing pronunciations.
(3) Get a human to provide Cyrillic prons, including accent marks, where a sentence has none. If it’s too time-consuming to do this for every word in the sentence, do it for the key words (the cloze and/or words where the stress is not obvious). Do not place accent marks on monosyllabic words.
I realize that these steps, especially item 3, will take time and possibly money. But Clozemaster is a service that people like me are paying for. If there’s time and money available for changing the appearance of the user interface, there should be time and money for ensuring that the information presented is correct.
I will post separately in this thread two tables that I’ve compiled. The first shows the pronunciation errors I’ve reported over the course of a month, while the second shows the posts in which I’ve talked about systemic errors.
If any native Russian speakers see errors in the pronunciations I found at Wiktionary, please let me know. I’m also curious whether other Russian learners have been aware of the bad pronunciations and if so, how they’ve dealt with them.
Thanks for reading through this long post.