In the new fast fluency (collection 1). Assuming it continues as well as the list goes on but haven’t checked much.
1 Like
The new Fast Track for Indonesian is now available! ![]()
![]()
Romanian, Norwegian, and Polish are translated/proofread and we’ll be working to make those available next. Tagalog should be completed soon, and we’ve started on European Portuguese.
More updates soon!
10 Likes
Russian has the New Fast Track, but is not listed in the progress bars at the top. You should give yourself some credit. ![]()
Also, realphabetizing the progress bars would make it easier for people to find a specific language.
5 Likes
Also, could you consider adding sentences lists for all of these languages in the section at the bottom of the Clozemaster dashboard.
For example, although they aren’t listed, Italian and Indonesian from English both have landing pages, but there are no sentences there.
I’m not sure whether you have curated sentence lists for all of these other languages.
P.S. I’m not sure why Italian from English has never been there as it was one of the first languages to be released.
3 Likes
Russian added and alphabetized!
Yes! Should be doable, thanks for the nudge. How are you using these lists?
4 Likes
My usage of these lists (well, so far only the German ones) is directly related to your question about the podcasts -
When you first made these lists, I thought they were interesting, but not something I would make great use of.
Similarly, when you announced the podcasts with LoFi background music, I thought that these were very good, but I couldn’t really see myself using them much because I like to be able to see what is spoken e.g. if there is a word that is unfamiliar and I’m not quite sure what it was, or else to add a sentence with such a word into a collection.
Then, when I went back to listen again to one of the podcasts of sentences in German, I realised that each set of 20 podcast sentences was the same as the 20 sentences in the list with the same name. I note that in the description of the YouTube video this is stated and a link provided, but this doesn’t work the other way round i.e. there is nothing in the sentence list description that states that there are podcasts or YouTube videos available that loop over the sentence lists.
So I then realised that this was much more powerful as a learning tool than the sum of its parts (podcast + sentence list)!
I realised that I could now listen to a podcast, and for any sentence that I thought was interesting I could find it in the sentence list to see how it looks written down, and then optionally click “Add to collection” if I want to practice it.
So that is how I would use the sentences (and how I have done it a tiny bit with German), however …
Firstly, I don’t use Spotify for my podcasts, and so I’d need an easy way of getting access to them from elsewhere (I personally use both Apple and YouTube Music (because they closed down Google Podcasts), but others might possibly use other tools). The link that you provided to be able to access the German sentences worked for me, but we would need something like that for each language.
Secondly, some of the languages that I’m currently putting most time into don’t have either podcasts, or sentences, or both (e.g. Turkish and Indonesian).
So, here is what I would very much like to request that you do -
- Add sentence lists for all languages for which you have produced a New Fluency Fast Track course.
- Make a set of podcasts for each of these languages for the same sets of sentences.
- In the sentence lists description for each language (or even for each list), state that these are also available as a podcast with LoFi background music, and put a link to the podcast (either by saying available on … and list several podcast platforms, or add an anchor.fm RSS link as you did before), and to the YouTube video if you continue to make those as well.
- … Advertise this feature.
Personally, I find that there are so many great resources and possibilities with Clozemaster, but many things aren’t easy to find, or else they aren’t advertised or marketted. Perhaps other people would be interested in the " podcast → sentence list → add to collection " workflow that I mentioned, but they might not have realised that these things are connected - even for the YouTube video, most people probably don’t click to reveal the full video description where the reverse link to the sentences is then available.
So that would be my request and reasoning for having more sentence lists … and complimentary podcasts.
2 Likes
Hi Mike, I have a few quesions about the new fast track collection I didn’t find an answer for:
- How many sentences are there (in average) for each cloze word?
- Based on what order are the sentences displayed? The cloze word frequency? Based on what frequency list?
- Is there any correlation between the collection number (1-10) and the CEFR level?
- When do you expect to roll out the new fast track for Romanian and Arabic?
Thanks.
4 Likes
@zzcguns thanks for the reply, super helpful, and sorry my slow reply!
Agreed! We’re working to improve this. Lists for Indonesian and Italian have been added, we’ll work on more soon. We paused on adding podcasts and YouTube videos as those require more time and effort - someone has to go in and upload all that. We’ll see if we can’t improve the existing lists like you mentioned, getting the corresponding YouTube videos and podcasts embedded and figure out the RSS feeds, then see if they get any further tractions / it’s worth getting more videos/podcasts created and uploaded. Any additional thoughts or anyone else that finds these particularly useful please let us know.
Edit: Italian and Indonesian are still generating, they should be available by the end of today.
- Looks like ~1.14 sentences per cloze. There end up being repeats as a result of translating from English into each target language.
- Based off an English frequency list - for the new Fast Track, we created sets of sentences in English, then have them translated into each language. More on the rationale above.
- No CEFR correlation. We are working on creating CEFR collections.
- Romanian is out!
 Arabic - we got bogged down with trying to get harakat added, perhaps we should just release it without harakat for now and get it added later when possible.
Arabic - we got bogged down with trying to get harakat added, perhaps we should just release it without harakat for now and get it added later when possible.
4 Likes
For everyone @here in this thread - what do you think if, for example, we just release the first 3 levels of the new Fast Track, so 3 collections of 1,000 sentences each, for some languages?
Our thinking is that we could more quickly release a subset for some less popular languages, for example Catalan, Latvian, etc., that we might not get to as soon otherwise in aiming for the full set of 10,000 sentences. Then we can add more of the collections later if it turns out people are tearing through the initial subset.
We can’t think of a good reason for why not. It’d be awesome to get more collections added for more languages, even if initially not the full on 10,000 we have in mind for the new Fast Track. But curious to hear if you have any thoughts/feedback.
17 Likes
I think it’s a great idea!
5 Likes
I can’t either. Three collections of 1,000 sentences could keep someone productively busy for a long time.
6 Likes
Hi! I see that the new fast track for Polish should be released soon. Is there any info on when that’s going to happen as I’m eagerly waiting for it ![]()
2 Likes
@mike thank you for your response.
So if I understand it correctly, finishing all 10 collections will get me, vocabulary wise, based on the clozes only, to C1. Am I right?
CEFR collections will be great.
Since Clozemaster helps with both active vocabulary (clozes) and passive vocabulary (rest of the sentence), may I suggest the following table as a guideline for the sentences for each collection?
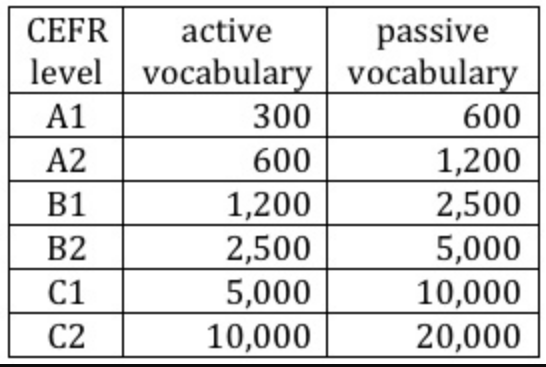
The numbers may vary, this is just from one source, but the rationale is that sentences with a passive vocabulary (non-cloze words) that’s limited based on the CEFR level will be more beginner friendly, make the retention of the vocabulary easier at the beginning and also make the start less overwhelming.
What do you think?
About Romanian - I’m still not seeing the new fast track in my account (I tried both on desktop and mobile).
Does it take time to update?
About Arabic and harakat - it should make it more beginner friendly, I think it will add a lot of value.
Is there any chance that in addition to the translation you can add the original text in Latin alphabet (e.g. marhaba)? It will help a lot with learning the alphabet and the reading skill and will make going through the sentences and learning the words much easier for beginners.
About your first 3 collections suggestion - I think it’s a great idea and you will be able to decide where to invest in the additional collections based in the popularity of the first 3 in each language.
4 Likes
I think the first 3 levels are a good idea. I think it makes more sense than waiting until all 10 are done to release.
Ps: still hoping to see hebrew mentioned eventually!
4 Likes
Within the next 6 weeks if all goes well.
What’s the source for that chart? Clozemaster counts different forms of a word as different words. So if C1 passive vocabulary counts “bebo” and “bebes” as different words in the 10,000, then it would appear so. If it’s 10,000 lemmas, then it may not, though the new Fast Track likely doesn’t have all 600 A1 words as the missing word for example, so it may be more biased towards higher CEFR level missing words.
That table is helpful for creating CEFR collections, thanks.
It should now be available, hit reply too soon ![]() Please let me know if you’re still not seeing it.
Please let me know if you’re still not seeing it.
Thanks for raising, still TBD.
4 Likes
The first 3 for Cantonese is now available! ![]()
4 Likes
Here’s the source for the vocabulary table:
I’m glad you find it useful.
Thanks for the explanation about the vocabulary.
About Romanian - yeah, I was too quick to reply ![]()
1 Like
I’m rooting for Catalan to come soon - an initial 3,000 would be great!
I’m enjoying the New Fast Track. I joined up around New Year’s. I’m a native English speaker, fluent Spanish speaker. My main language that I’m learning is Lithuanian, and I’ve gotten through the first 1,000 words. They seem pretty high quality from what I know. The explanations I see using the Chat GPT feature (which I love) match what I’ve learned in grammar books. It even pointed out a few errors that I found myself (and did report).
As a point of comparison, I’ve simultaneously been plowing through Spanish - to kind of see how the collection progresses, and to identify maybe a few words here and there that I’ve forgotten. I’m through 9, 780 - so almost there. And the collection to me seems very high quality with few to no errors. (I do have a Master’s degree in the language, so while I’m not infallible I’m also not talking out of complete ignorance.)
Anyway thanks Mike, for all the great work on this. It’s a very impressive tool - seems to me it is the best tool currently available for Lithuanian in particular.
6 Likes
I think this is a great idea. I’ve recently started learning Tagalog and being able to make a start on the first 3000 would be really helpful. I’m not certain whether that particular language would be included in this proposal as it sounds like it’s coming soonish anyway, but I can see it being useful for others learning other languages too.
2 Likes
Just logged in for the first time in many Months and found you just added the new Romanian content - excellent! Any news on the Norwegian release as I see mention of it releasing a month ago, but can’t find it yet?
2 Likes