Sir, yes, Sir!
Well, I actually use the “Round history” option around 10% of the time - and that means at least 10x a day.
I use it because after listen and type correctly a sentence, I feel that I didn’t fully grasp the concept or the feeling in that sentence, so I go after it to reset it. About 90% of the time this is the case.
The duplicates are interesting. I didn’t have to search much to find quite a few. I suspect for certain languages there are quite a lot, although mike would be best equipped to confirm this.
In your thread (Fluency Fast Track in German has the same cloze twice in the same round), I posted regarding duplicates in the Mandarin Chinese fast track. You can see that the duplicates appear to be different forms of the word in English which happen to be the same in Mandarin. For example “married” and “marry” both end up the same (结婚) in Mandarin. Same with “and” and “with” both being ”和”, “them” and “they” both being “他们”, and “I” and “my” both being ”我”.
I understand it isn’t straightforward how to address this, and in fact it may be good to have these duplicates to show how they are used differently. However, I do believe it is misleading and/or confusing to state that each level includes 10,000 unique words.
I would appreciate seeing the true number of unique words for the sake of transparency so I know how many I have actually learned.
5 Likes
Well put, I’ve requested the same numbers for the same reasons for Japanese. Apparently it is a thing that could happen, maybe we will find out soon. There’s utility to these stats but it’s also just a lot of fun to keep track of them (how many characters/how many words etc)
![]() New languages have been added !!!
New languages have been added !!! ![]()
There are now 18 languages with the new Fluency Fast Track judging by the “Sentences List” list at the bottom right of the Clozemaster dashboard screen.
Newest additions are -
- French (has been available for a few weeks)
- Ukrainian (2nd time lucky
 )
) - Persian / Farsi
- Turkish
- Swedish
- Lithuanian
@mike still needs add these to the first entry of this thread (as at 2am AWST 29th June 2024), but they appear to be available now.
(N.B. I haven’t verified this by starting to study all of these languages, as it would trigger notifications that I would then have to delete).
Now that my “waiting for the new course” excuse has gone, it looks like it’s finally time for me to start using Clozemaster for Turkish …
6 Likes
russian update finally, thanks!!!
5 Likes
Duplicated cloze word in new FFT (Russian). Some have already mentioned this but I feel like I have to post because this is ridiculous. The description of Fast Track Level 1 is “Most common words 1-1,000 are used as the missing word.”, with the 1000 most common words occurring over 1,000 sentences. But just as an example есть is used as the cloze word 4 times in Fast Track Level 1. Unless I’m missing something this is a blatant misrepresentation of what’s in FFT. Why go through all the work of making FFT better and having some big release but not even do a simple check of making sure you don’t have duplicated cloze words when you imply you don’t. I love Clozemaster but I find this so aggravating.
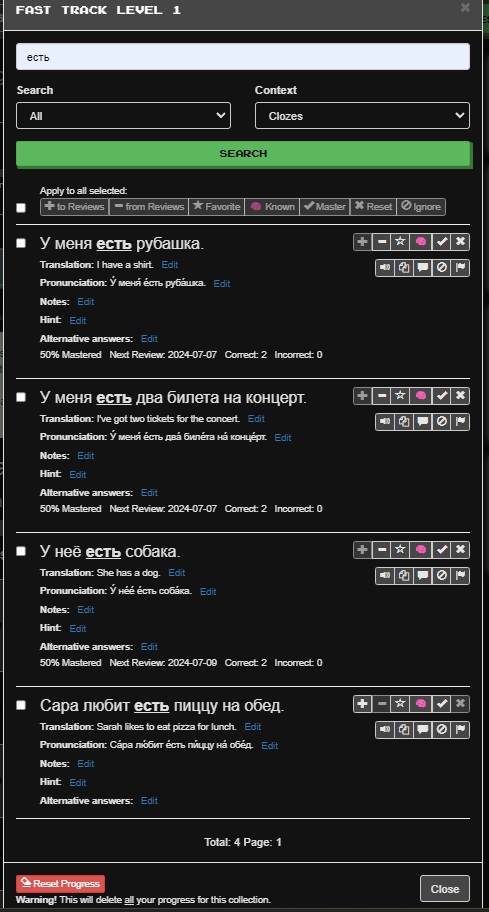
3 Likes
Thanks for posting about the dupes in Russian and sorry for the aggravation. We’ll work on getting those cleaned up where possible. There will still be some duplicated cloze words. Good point about “Most common words 1-1,000 are used as the missing word.” being unclear. We’ll update it to something like “Missing words are in the range of 1-1,000 of the most common words, though there may be some not used as the missing word or some missing words used more than once.”.
The process we went with is to essentially translate the same set of 10,000 English sentences into as many languages as possible. The issue, however, is that although the English set has 10,000 unique cloze words, they don’t always translate into 10,000 unique cloze words. Having super high quality content seemed worth the trade-off.
A potentially better alternative approach we might try in the future could be to attempt to select 10,000 words in Russian, for example, that seem worth learning from a frequency list, then create an example sentence for each of those words and have them translated into English. The thought, however, was that this approach would require much judgement from the person creating/selecting/proofreading the word list as well as the sentences, and it would be therefore much more difficult to scale vs a straight translation project - translate/proofread this set of sentences from English into Russian and keep the word in {{}} the same to the extent possible.
12 Likes
Thank you for the response mike. I appreciate the explanation of the process and why it was chosen. Makes sense.
4 Likes
Mr. @mike is amazing, isn’t he?
But I’m still looking forward in order to do English from Portuguese… ![]()
3 Likes
Would love if we could get Swahili at some point! So hard to find good input material.
1 Like
Hi. I started Swahili with Memrise during covid, such a beautiful language. Can’t seem to get into the Memrise course now, it has all changed, so Swahili here would be more than interesting.
2 Likes
Hi! Any plans for Icelandic to get updated? I know it´s probably way down the list. Thanks for all your hard work!
4 Likes
I briefly checked out the new fast track on swedish and i love how its set up. Will all languages eventually have it? My priority language right now is hebrew and i dont see it mentioned here. I’m also learning greek but i DO see that one mentioned plus i dont think I’m quite ready for clozemaster yet when it comes to greek anyway.
2 Likes
I see that I can now learn English from Portuguese. This is AMAZERFUL! ![]()
![]()
![]()
I also see no one has mentioned that yet - Maybe Portuguese was privileged?
Pity I can’t do Listening > Transcribe (Hard) on it. ![]()
Could it be that it will be implemented soon? ![]()
2 Likes
In case anyone has been waiting for Greek: it’s apparently finished, despite the first post of this thread not showing that.
2 Likes
I love the new fast track! The sentences are much higher quality, and I also appreciate that there are far fewer sentences that are super inappropriate to be popping up while I’m doing Clozemaster at work in my downtime.
I love that it’s split into 10 sections, it feels much less daunting and I actually feel like I’m making progress. BUT, it is super frustrating that I can’t review all the fluency fast track levels at the same time. Review all probably works for some users, but since I’m just returning to clozemaster, I have 3k reviews of legacy fast track waiting for me, and also some most common words stuff that I was doing with multiple choice rather than typing.
Any chance of adding a function to review clozes from the same collection all together, (new fast track, most common words), and/or select which collections to review? I want to be able to review the new fast track levels as a set, and same with MCW, so that I can use my preferred settings for each, and keep up on the collection that is my priority (FFT) without reviewing them individually and ending up with a bunch of small review sessions with the same few sentences grouped together.
7 Likes
Can someone clarify whether the frequency grouping of words in the new FTT is based on the target language or on English? I ask because I encountered the word ‘attrezzatura’ (equipment) in the second fast track level for Italian (the second thousand most frequent words?).
But in this document (https://www.top10000words.com/Italian/top-10000-italian-wordshttps://www.top10000words.com/Italian/top-10000-italian-words) it is listed as 6079th most frequent.
On a English frequency list (https://www.top10000words.com/english/top-10000-english-words, ‘equipment’ is listed as the 3068th most frequent.
All of which leaves me puzzled what the source of the frequency word lists are. Please excuse me if I have a fundamental misunderstanding of how the new FFT works.
In a previous post in this thread - New Fast Track Tracker - #69 by mike
@mike said the following -
The process we went with is to essentially translate the same set of 10,000 English sentences into as many languages as possible. The issue, however, is that although the English set has 10,000 unique cloze words, they don’t always translate into 10,000 unique cloze words. Having super high quality content seemed worth the trade-off.
Now, as you appear to be studying multiple languages from English, you can take a look at for example the New FFT Level 1 list in those languages. By using “Manage Sentences” under the three-dots sign for those collections, you should see that the sets of sentences are the same (perhaps in a slightly different order).
So then, for each sentence there is some word chosen as the cloze, and this appears to be the one that is as close as possible to a specific English word in that sentence that is mapped as that sentence’s unique word for the purpose of getting the 10,000 words and sentences.
This does however mean that a word in the target language can show up as the cloze word multiple times in a collection or collections. For example in Turkish from English in New FFT Level 1, the word “çok” is the cloze word in 5 different sentences (“çok” is a common word in Turkish). I note however, that in each of the English sentences it translates as something different - “very”, “too”, “such”, “a lot”, “lots”.
Also, sometimes a single English word does not translate to a single word in another language, and these cases can also lead to a cloze word being repeated in the target language as a single word needs to be chosen as the cloze (actually that isn’t true as Clozemaster allows contiguous multi-word closes, but that isn’t something that fits with the idea of the FFT).
Examples of these instances in Turkish are repeated use of “zaman” as a cloze as part of “ne zaman” meaning “when”, and “her zaman” meaning “always” N.B. a semi-literal translation of the Turkish words would be “what time” for “ne zaman” and “each/every time” for “her zaman” (i.e. “ne” - “what” ; “her” - “each/every” ; “zaman” - “time”).
Therefore, in Italian the cloze word “attrezzatura” would not have been the word chosen to be the cloze based on frequency. Instead the English word “equipment” would have been the word chosen, and then “attrezzatura” would have been identified as being a good match to use as a cloze in the Italian sentence. As you suggest in your message, there are multiple sources of frequency lists in any language, and so for some English frequency list the word “equipment” could have a much higher ranking than in the one that you gave as an example.
Now whether the choice of “equipment” is based on word frequency or not I don’t know, as the way that @mike described this it could be the case that the sentences have been chosen not on the basis of most common words as much as on common sentences/ideas.
On a personal note, I don’t mind a few repeated clozes or words that are uncommon appearing earlier than they probably should. I find these sentences useful as whole sentences, much more so than just for the clozes contained within them. If a word shows up in a sentence that I don’t know, and don’t remember seeing it as a cloze, then I will search for it as a cloze by using “Manage Sentences” for that collection. If the search result is empty then I’ll copy that sentence to a custom collection and change the cloze word in the sentence to be the one that I’m interested in.
3 Likes
Thanks for clarifying how the clozes on the new FFT were constructed!
1 Like