Another thing, here’s the image for spanish 10,000 most common words I’m doing.
So this section contains 10,000 sentences from the “5,001 to 10,000” most common words in Spanish right?
Do I know exactly how many of the “5,001 to 10,000” are actually used? Because there could be some words that have 3 sentences and some 5 and some 1 right? So it may be that I am not going through the full 5,000 different words (of the 5,001 to 10,000 most common spanish words).
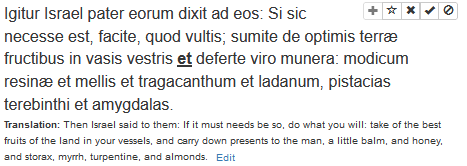
Also, what does the “456” mean? It means the number of sentences of the 10,000 I’ve gone through right? And what’s the green (0%) in the last column refer to?
I don’t click the “Review” button. Yet I’m still seeing the same sentences when I do the most common words. Is that meant to be the way it works?
The default settings will show you some reviews in every round. If you want to change it so you only see new sentences, you can do it under Review Settings on your dashboard:
So this section contains 10,000 sentences from the “5,001 to 10,000” most common words in Spanish right?
Correct.
Do I know exactly how many of the “5,001 to 10,000” are actually used?
Not to my knowledge.
Because there could be some words that have 3 sentences and some 5 and some 1 right? So it may be that I am not going through the full 5,000 different words
That’s correct. Clozemaster draws its sentences from Tatoeba, so if a word isn’t in Tatoeba it won’t be here.
Also, what does the “456” mean? It means the number of sentences of the 10,000 I’ve gone through right? And what’s the green (0%) in the last column refer to?
456 is the number of sentences in that category that you’ve played. The green % is for the sentences you’ve fully mastered (played once and reviewed a further three times, or manually set to mastered).
Thanks for your help. I’m not sure who you are, but I don’t understand why all these pieces of information aren’t in some section of the website (I’m assuming it isn’t since I’ve hinted at this in my previous messages). Someone who works for Clozemaster should be writing all this up as people do have questions about all this!
Also, I’m wondering how often more words are put into Clozemaster. Do we get updates if that’s so? I’m interested to find if more and more words are being added for Spanish.
So even though I have not finished the 10,000 words, I tried the 20,000 Most common words section in Spanish, which I guess should be from the 10,0001 to 20,000 most common words in Spanish.
I got these words: “cierres” - subjunctive of “Cerrar” (close) and “Paremos” - imperative (I think) of “Parar” (stop)
I’m wondering if these are really that “rare” - i.e. outside the most common 10,000 words in Spanish. I am an ESL teacher so I know that “stop” and “close” in English are both very common - in fact, in the top 2,500 most commonly used words according to Macmillan.
Of course, Spanish isn’t English, but I am just expressing my doubts as to whether “cerrar” and “parar” are outside the top 10,000 most commonly used Spanish words. I’m assuming they way words are ranked include all forms (however conjugated, and whether imperative or subjunctive, etc.). If so, I can’t imagine these two Spanish words to be so uncommon.
I may be wrong but I’d love someone’s comment. Unless my understanding of how Clozemaster works is wrong. Thanks
I’m do not know anything about the sourcecode of Clozemaster. But all of the sentences are from tatoeba and i think there is no code for conjugation in Clozemaster. The occurence seems to be the occurerence of exactly this byte sequence of the word in the sentences imported from tatoeba.
AFAIK a word in clozemaster is generally a unique set of characters, so you will get multiple words for each conjugated verb, or adjective, etc. Rarer conjugations of common verbs may be in uncommon word collections.
This! The frequency list we use includes conjugated/declined/inflected forms, so less common conjugations of common verbs are further down the list / considered more difficult.
Nope, and right Clozemaster uses the most “difficult” word in the sentence as the missing word (the least common according to a frequency list for that language), so it may also be that you end up seeing a number of words that are in a given Most Common Words range but are never used as the missing word.
Agreed! Thanks for all the questions - work in progress on a knowledge base / improved FAQ. And ideally we’ll keep improving the UI to make the answers to these questions more obvious from the UI itself / just by playing.
Not often at the moment, though we’re working on changing that. I’d also mentioned about potentially splitting some of the Most Common Words collections and adding a “part 2” to the Fast Track above. We may send out an update, but ideally we’ll have it automated such that it occurs every few weeks/months and you’ll simply see more sentences in the collection you’re playing
Also it’s worth noting that for Spanish there should already be plenty of content to keep you busy for a looong time It sounds like you’re looking at the 5,000/10,000/20,000 Most Common Words collections, which for Spanish have nearly 24,000 sentences combined - the equivalent of reading the first Harry Potter novel nearly 4 times. And by the time you get through it all (and perhaps the 50k Most Common collection) you’ll probably want to move on to more native-level content - reading books, watching movies, etc.
Any other questions or anything I missed please be sure to let us know!
My understanding is that this, sadly, will sometimes make valuable words not end up as clozes, when they are masked by some even more difficult word in a sentence. And, that “difficult” word may be a name or something quite irrelevant.
This is the part I don’t understand. Most frequency word lists don’t have different conjugations as separate words. And I guess this is the reason I’m seeing so common words in a list (in a less common conjugated form) that should contain less common words.
Might you be able to share any of these lists? We likely won’t change the current approach, but we love a good frequency list as much as anyone and perhaps we can use them in other ways.
I’d counter that it might be a bit much to see the past tense subjunctive in the 100 Most Common Words collection when you’re presumably a beginner looking to work through the most common words, unless of course it really is a form you’re likely to see daily.
I don’t see how a language learning tool would be very useful if it didn’t require you to conjugate verbs in many different forms. I needed a TON of repetition of reading, hearing and reproducing the various French verb forms for them to start seeming natural.
Plurals can be frustrating, in that words like “teachers” and “elephants” sometimes occur in the less frequent word categories, when you’ve already covered “teacher” and “elephant” earlier. However, sentences like that are a small percentage of the overall collection. You can mark them as “ignore” so you won’t see them again after the first time.
I’m not familiar with Spanish word lists, but more of English word lists. For example, Oxford, Cambridge, Longman, MacMillan all have their own list. As far as I know, and I’m an ESL teacher, and don’t teach Spanish or other languages, the way people use word lists are that they include all conjugations, etc.
I can understand your point of view and Kadrian’s point of view. The subjunctive in Spanish is normally a more intermediate to advanced teaching. On the other hand, the way I use CM is that I learn grammar (verb conjugation) separately and maybe it’s because I’m already at an intermediate level to begin with. But anyway, that’s just a different point of view and so I understand where CM is coming from.
Interesting that elephant is ranked so high in frequency. Maybe English is different from Romance languages for having so few conjugated forms and not having gender/number agreement, and also different from other Germanic languages in not modifying by case as much which leads to fewer unique ‘forms’ per ‘word’. (Not saying English is simpler). Doubt it is either zoology or idiomatic usage which would be driving the frequency.
ok this explains why in some languages you very rarely see sentences related to the absolute most common words (maybe like 1-10) for example ‘de’ in French or ‘die’ in german.
Maybe you’re right regarding Oxford - and I assumed Oxford would do it differently. Maybe there are different lists. Even though I mentioned Oxford and Cambridge, I don’t really use their list. I’m more familiar with Macmillan and Longman and both do it differently from oxford if what you wrote is correct regarding oxford.
Of course in English, you don’t seem to have as many conjugations of verbs as in spanish perhaps.
You often hear people say that if you know the most common say 2,500 or 3,000 words in English (I’m not sure if this applies to other languages), you would know 90% of what’s written/spoken every day (or something to this effect). Whether or not this applies to other languages, I’m not sure. But my understanding of this is that you’re not talking about the top 2,500/3,000 most common words if you’re seeing each conjugation of a verb (or even plural vs singular) as separate words altogether.
I’m not sure where that oxford list was found, but according to Macmillan and Longman, elephant is definitely not in the top 2,500/3,000 most common words.
This list only includes verbs once (with elephant somewhere in the top 3,000).
But my understanding of this is that you’re not talking about the top 2,500/3,000 most common words if you’re seeing each conjugation of a verb (or even plural vs singular) as separate words altogether.


 Clozemaster uses the most “difficult” word in the sentence as the missing word (the least common according to a frequency list for that language), so it may also be that you end up seeing a number of words that are in a given Most Common Words range but are never used as the missing word.
Clozemaster uses the most “difficult” word in the sentence as the missing word (the least common according to a frequency list for that language), so it may also be that you end up seeing a number of words that are in a given Most Common Words range but are never used as the missing word. And by the time you get through it all (and perhaps the 50k Most Common collection) you’ll probably want to move on to more native-level content - reading books, watching movies, etc.
And by the time you get through it all (and perhaps the 50k Most Common collection) you’ll probably want to move on to more native-level content - reading books, watching movies, etc.